Need help getting started? Here we have created content around some of the most common questions from the community. Dive in and hit the ground running.

Empower Your Research with Efficiency and Precision

Follow Sarah's Journey as She Turns Stress into Enjoyment and Maximizes Research Impact in the Literature Review Process.

Read this guide to learn more about the Super Search function, allowing you to search across all your documents at once.
This series showcases some of the amazing work of our pioneers. From building mechanical twins for optimising manufacturing processes to solving racial injustice at universities.

This post is the fifth of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.

This post is the fourth of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.

This post is the third of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.
Empower Your Research with Efficiency and Precision
Follow Sarah's Journey as She Turns Stress into Enjoyment and Maximizes Research Impact in the Literature Review Process.
This post is the fifth of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.
This post is the fourth of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.
This post is the third of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.

This post is the second of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.
Read this guide to learn more about the Super Search function, allowing you to search across all your documents at once.

This post is the first of a series of posts showcasing some of the amazing research projects from our community of Lateral pioneers.

This guide gives you 3 ways of structuring your concepts in Lateral; Research Themes, Structural Concepts, Keywords.

The reason for writer’s block in academia often comes down to the challenge of sorting out the thoughts of sophisticated research, and how to communicate it.

In this blog, I describe the limitations of Dropbox and Google in the space of research, and propose Lateral as the much needed alternative.

Welcome to this beginner’s guide, dedicated to help you get the most out of the Lateral app!

In this blog, I outline some organisational techniques and the best digital collaborative tools for successful student group work.

I hope the following six things to consider and organise will make the complex dissertation writing more manageable.

We built a better tool for research and literature review.

We want to make it possible for any expert to capture and scale their expertise.

Breaking documents into “chunks”, like sections and subsections, is easy for humans, but surprisingly hard for computers. In this post we explain why this is, why it’s a valuable problem to solve, and we introduce our new solution.
This post describes a simple principle to split documents into coherent segments, using word embeddings.
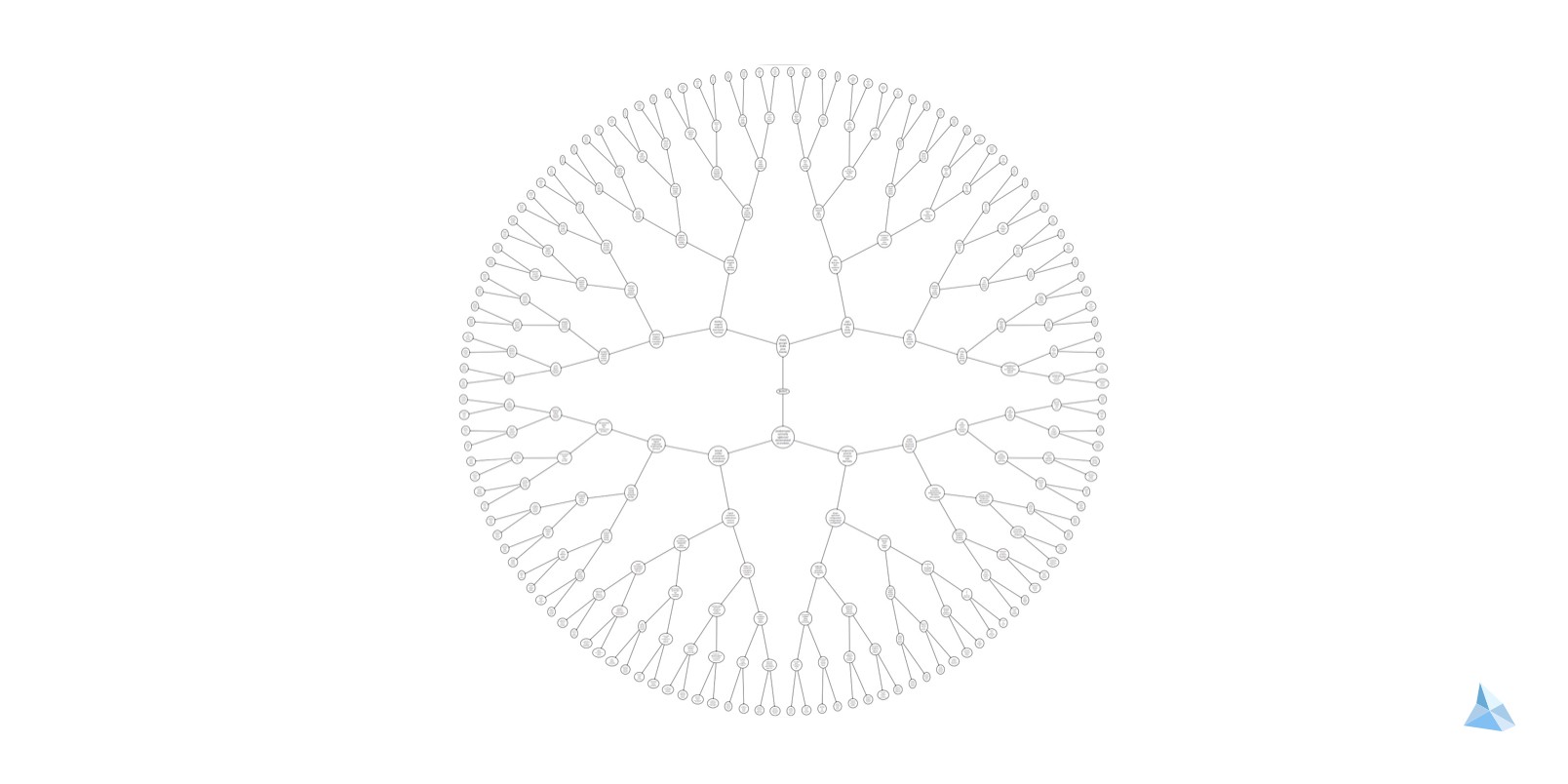
In this blog post we describe an experiment to construct semantic trees and show how they can improve the quality of the learned embeddings in common word analogy and similarity tasks.

How can you learn a map from a German language to an English language word vectorisation model, to enable crosslingual document comparison?

How to create a VHD that is fully compatible with Azure from an Ubuntu Cloud Image base.

By labelling documents with the users who read them, we used fastText to hack together a “hybrid recommender” system.

In this blog post, I will create a Chrome extension that modifies this blog to set a custom background and to modify the HTML
Build your own Give me five Chrome extension using our open source template, based on our popular NewsBot Chrome extension for recommending news.
What kind of language do British parliamentarians use? We used the Lateral API to provide an overview by clustering debates and creating word clouds.
We migrated our multiple PostgreSQL databases between cloud providers. Key was to keep downtime to an absolute minimum. This is what we did using Londiste.
Previously we wrote about how machines can learn meaning. An exciting opportunity of this approach is that it also enables teaching machines new languages.
Announcing our Article Extractor API! Rapidly extract the text as well as image, title, keywords, author and more from any article and blog post URLs.
We’ve been doing occasional work on an approximate nearest neighbours (ANN) vector search tool, written in Python. Today, we are open sourcing it.
pjax is a jQuery library created by Chris Wanstrath. As we recently decided to use it, I thought it might be valuable to share our experience.
The arXiv is a repository of over 1 million preprints. It is truly open access, and excellent for testing language modelling / machine learning prototypes.
This article is about our NewsBot chrome extension, the fastest way to find related articles.
Computers consist of on/off switches and process meaningless symbols. So how is it that we can hope that machines learn meaning of words and documents?
Today I am going to talk about API documentation tools. Specifically, the ones that we use at Lateral to create the Lateral API documentation.

If a machine is to learn about humans from Wikipedia, it must experience the corpus as a human sees it and ignore the mass of robot-generated pages.
By ignoring citation graphs and keywords, you can discover research and researchers you never knew existed. Check it out!

We wanted to create a fast search experience for the visualiser that lets you search the full text of documents as well as their titles to quickly find a document to get Lateral recommendations for.
The Lateral tech team opinions on various API as part of the APIDays Berlin & APIStrat Europe conference Speedhack.



