





Introduction
Reddit is a popular social news aggregator and discussion site with hundreds of thousands of subreddits devoted to every topic one can imagine. One special kind of subreddits are the "Ask" forums where questions are posed and answered among subscribers. A particularly interesting subreddit is AskScience, where questions from various scientific disciplines are discussed in a very informed manner, giving a lot of references and different angles on a topic. We wanted to take this data as an opportunity to develop a workflow for deriving datasets from Reddit and to analyse them using the Lateral Intelligence Platform.
Getting data out of Reddit
Reddit provides an API for accessing its data. A particularly nice library for using the API from within Python is PRAW, the Python Reddit API Wrapper. Once you've set up a user account on Reddit and registered for a developer ID and secret, connecting to the API via PRAW is very easy:
<pre>
import praw
reddit = praw.Reddit(client_id=YOUR_CLIENT_ID,
client_secret=YOUR_CLIENT_SECRET,
password=YOUR_ACCOUNT_PASSWORD,
username=YOUR_ACCOUNT_USERNAME,
user_agent=NAME_OF_YOUR_APP)
</pre>
This returns an object for interacting with the different types of information on Reddit, such as subreddits, submissions, comments, etc. To work with a specific subreddit, in our case AskScience, a Subreddit object is generated:
<pre>
subreddit = reddit.subreddit('AskScience')
</pre>
This can be used to extract for example submissions or comments from AskScience with the option to specify various search criteria:
<pre>
# Get titles of submissions between two UNIX timestamps
for submission in subreddit.submissions(start=1478592000, end=1478678400):
print(submission.title)
# Get authors of 25 most recent comments
for comment in subreddit.comments(limit=25):
print(comment.author)
</pre>
See the PRAW documentation for more details on how to use the Subreddit object. One restriction of the API is that it only returns a limited number of results, usually up to 1000. Therefore, to get all data for a specific period of time, it is easiest to iterate over short periods that will most likely have less results than this limit. Following this discussion on redditdev, we used the search function of the Subreddit object and iterated over individual days:
<pre>
query = 'timestamp:%d..%d' % (start_day.timestamp(), end_day.timestamp())
submissions = list(subreddit.search(query, sort='new', limit=1000, syntax='cloudsearch')
</pre>
This gives a list of all submissions between start_day and end_day from which information can be extracted like this:
<pre>
for submission in submissions:
submission_text = submission.selftext
submission_title = submission.title
submission_date = submission.created_utc
# etc.
</pre>
This data can then be sent to the LIP API for analysing document similarities. In order to derive a dataset for both content-based similarity as well as hybrid recommendation, we decided to treat a post including all of its comments as one document and the original author as well as all commenters on that post as users that interacted with this document.
### The dataset
By extracting the AskScience posts for the years 2013 to 2016 we managed to assemble a dataset of 102,962 documents with 226,084 users and 717,425 interactions. As can be seen on average the interaction data is very sparse, with only around 7 comments per post and each user on average commenting only three times. Also, there is a large variance in user activity as shown by the following graph displaying the sorted interaction counts for the most active users.

Other valuable data that can be extracted in the case of the AskScience subreddit is the field of science, as posts are usually tagged by the scientific discipline. The top tags according to their count are:
<pre>
Physics: 26368
Biology: 17322
Astronomy: 8518
Chemistry: 7935
EarthSciences: 5692
HumanBody: 5076
Engineering: 5075
Medicine: 4873
Neuroscience: 3155
Mathematics: 2814
PlanetarySci.: 2549
Computing: 1932
Psychology: 1905
Paleontology: 571
Anthropology: 539
Linguistics: 526
SocialScience: 371
Interdisciplinary: 306
Economics: 272
Food: 231
Archaeology: 168
PoliticalScience: 55
</pre>
This also makes the dataset suitable for training a tag classifier that predicts the field of science based on the content of a post.
Recommending similar posts
As a first application of the newly generated dataset, the Give-me-Five Chrome extension can be used to search for posts that are similar to the page you're currently viewing in the browser. This for example works nicely on Reddit, for detecting duplicate posts or to get a different angle on a topic by seeing similar questions:
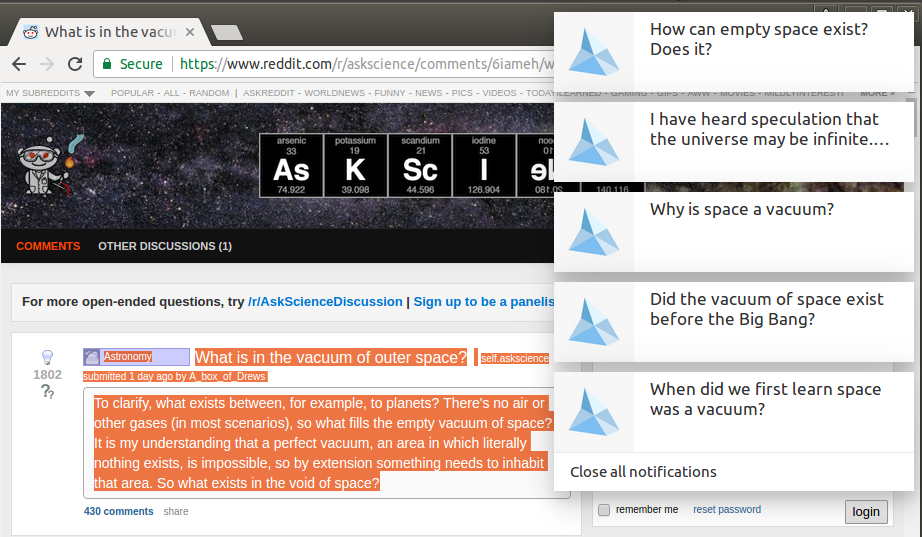
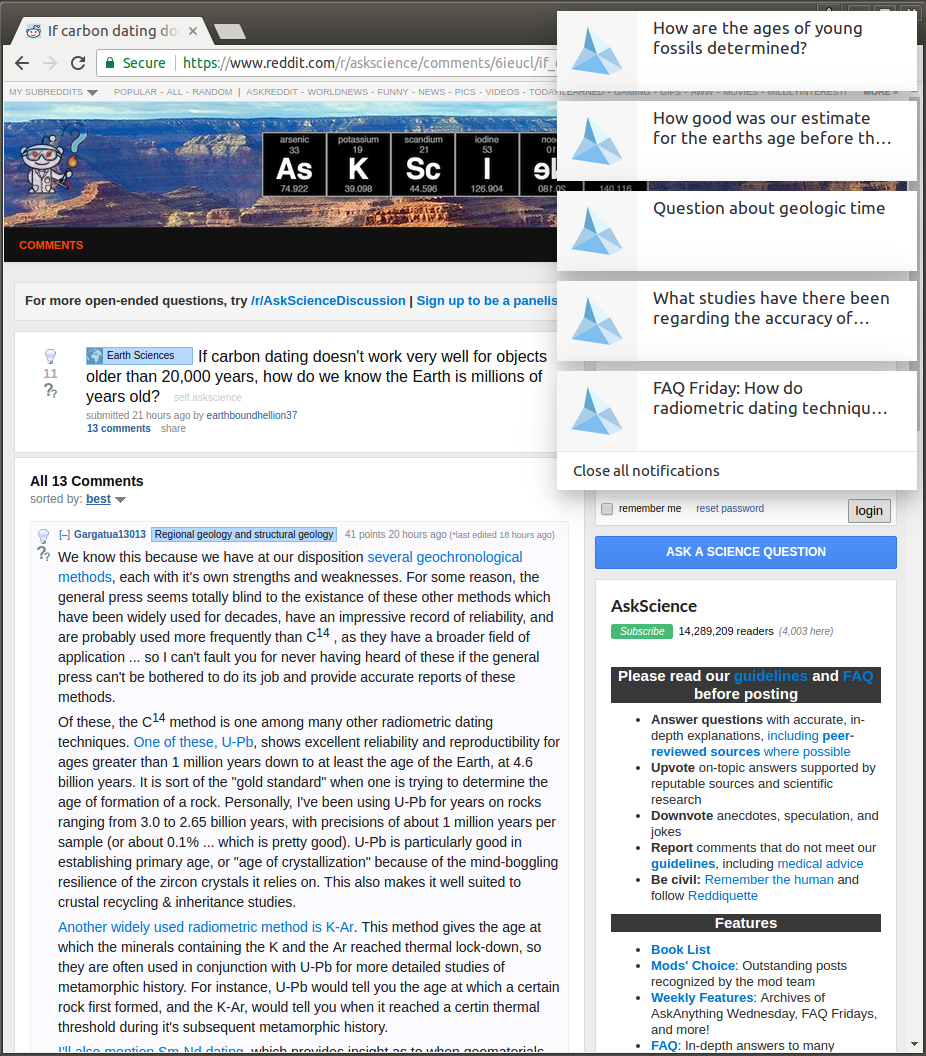
It also is very helpful when browsing other sites, such as news articles, in order to find out about related discussions on Reddit:
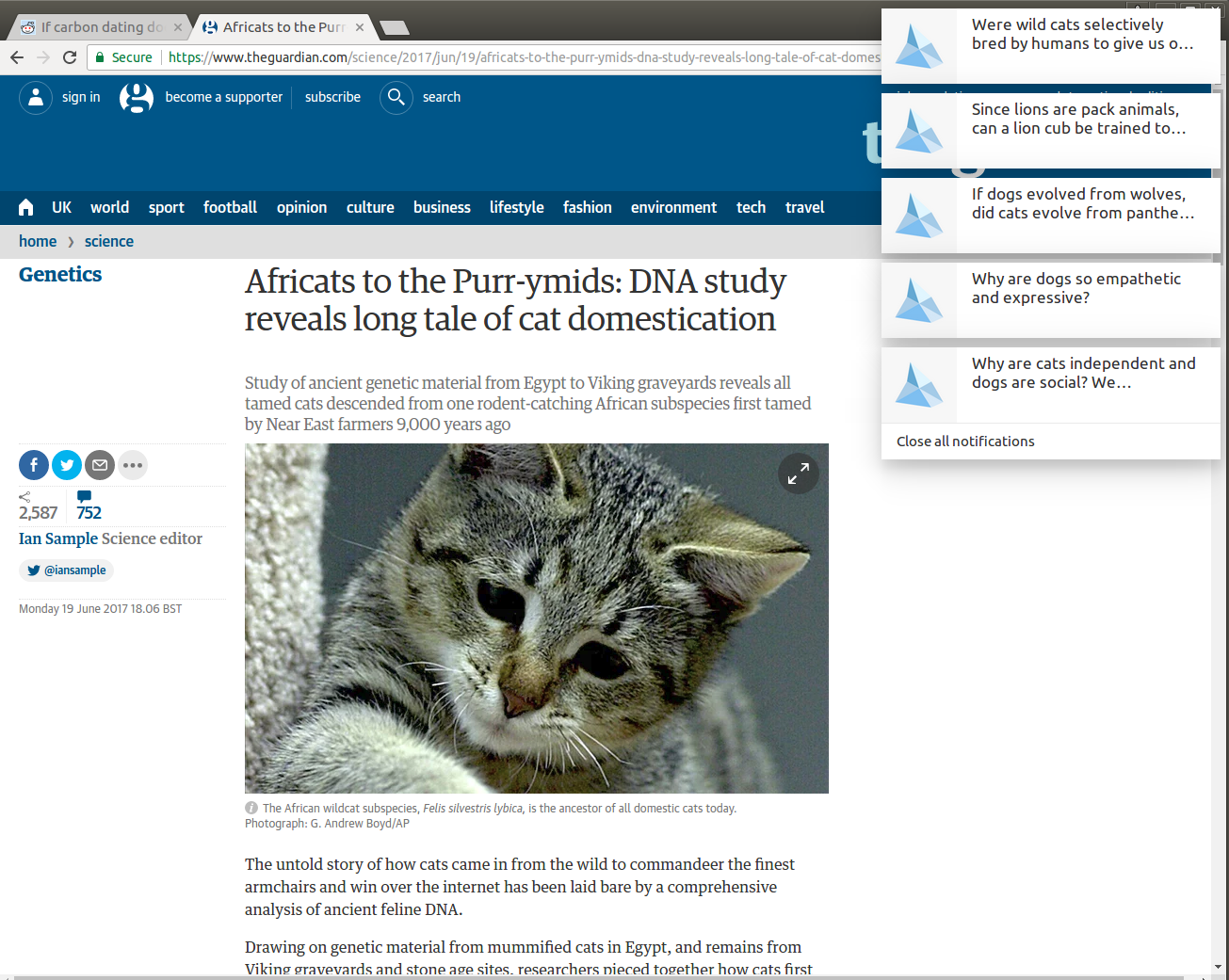
As a next step it will be interesting to use the user-post interaction data to train a hybrid recommender and compare it with the purely content-based approach. Another experiment in planning is to use the tags for the fields of science to train and benchmark various tag classifiers.


