




Introduction
Word vector models represent each word in a vocabulary as a vector in a continuous space such that words that share the same context are “close” together. Being close is measured using a distance metric or similarity measure such as the Euclidean distance or cosine similarity. Once word vectors have been trained on a large corpus, one can form document vectors to compare documents based on their content similarity. A central question is how to obtain “good” word vectors in the first place. For this various models based on neural networks have been proposed, one of the most popular ones being word2vec. In the “continous-bag-of-words” (CBOW) architecture of word2vec, word vectors are trained by predicting the central word of a sliding window given its neighbouring words. This is formulated as a classification problem, where the correct central word has to be selected among the full vocabulary given the context. Usually one would use a softmax classifier as the top layer of such a network. However, for the softmax the training time grows linearly in the number of possible outcomes, making the method unsuitable for large vocabularies.
Hierarchical softmax
Hierarchical softmax has been proposed in the context of language models to speed up training by Morin and Bengio (2005), following prior work by Goodman (2001). The idea is to decompose the softmax layer into a binary tree with the words of the vocabulary at its leaves, such that the probability of a word given a context can be decomposed into probabilities of choosing the correct child at each node along the path from the root node to that leaf. This reduces the number of necessary updates from a linear to a logarithmic term in the vocabulary size.
To choose a concrete tree for training a language or word embedding model, a number of techniques have been proposed. The original work by Morin and Bengio built the tree manually using hierarchical relations extracted from WordNet. Mnih and Hinton (2008) used a bootstrap variant where word vectors were trained based on a random tree, after which those were used to derive a semantically inspired tree by top-down clustering. The subsequent training using this semantic tree provided significant improvements over the random tree. Finally, Mikolov et. al. (2013) used a binary Huffman tree based on word frequency counts that focussed solely on training efficiency by assigning the shortest paths to the words that occur most often. This is also the version of hierarchical softmax that is implemented in Google’s word2vec code and Facebook’s fastText library.
Using semantic trees to train word embeddings
The idea to use a semantic tree seems natural, given that at each node, a binary classifier has to decide whether the given context vector fits better to the left or right child node. If the tree is built without any semantic knowledge, very similar words could end up on separate sides, making it very hard to train a good classifier and thus get a consistent error term for backpropagation. Imagine, for example, that the sentence “cats and dogs are animals” is the current context window, so that the word “dog” should be predicted from the context “{cats, and, are, animals}”. If, for example, the words “dog” and “dogs” are in separate child nodes at a very high level of the tree, the classifier most likely won’t be trained to achieve a high confidence. The same holds true if, for example, different animals are separated into different child nodes at an early stage.
The papers cited above that use semantic trees are all dealing with language models, i.e. predicting the next word given neighbouring words. The quality of a trained language model is usually evaluated using perplexity. In the context of word embeddings, this prediction task is only a tool to obtain good word vector representations, and it is not clear whether training methods that produce better language models actually transfer to better word embeddings. Therefore we wanted to try the approach of Mnih and Hinton (2008) for training word vectors from a corpus of Wikipedia documents and evaluate them using common word analogy and word similarity tasks.
Experiments
To train word vectors using hierarchical softmax with arbitrary trees, we modified the fastText code to accept a parameterization of a precomputed binary tree as an additional parameter.
In order to obtain a first set of word vectors, we trained a CBOW model using fastText on a dump of English Wikipedia from 2013 that has been filtered to contain only articles with at least 20 page views. This amounts to 463,819 documents with 498 million words. The hyperparameters we used were
<pre>
-minCount 25 -minn 0 -maxn 0 -t 0.00001 -lr 0.05 -ws 10 -epoch 3 -loss hs
</pre>
This means that only words that occur more than 25 times in the corpus are considered, there are no vectors trained for character n-grams, and training is run for 3 epochs with learning rate 0.05, subsampling parameter 1e-5 and window size 10.
The dimension of the embeddings was set to 50, 100, and 400 to assess the influence of the dimension on the performance. Using the -loss hs parameter for the hierarchical softmax loss function implies constructing a Huffman tree. Thus, from a semantic point of view, this tree can be considered random, giving a similar baseline as in Mnih and Hinton’s paper.
After the training finished, the resulting word vectors were clustered into a binary tree using a two-component Gaussian mixture model with spherical covariances. In the beginning, all word vectors are used and split into two components based on the posterior probability the GMM assigns to them. Then, at each step, all the vectors that are assigned to a leave node are split again into two components until the leaves of the tree only contain one word. Concretely, given a node of the tree with vectors node.vecs, the assignment to the left and right child nodes is computed as:
<pre>
from sklearn.mixture import GaussianMixture as GMM
gmm = GMM(n_components=2, covariance_type='spherical', verbose=0, max_iter=10)
gmm.fit(node.vecs)
classes = gmm.predict(node.vecs)
vecs_left = node.vecs.iloc[np.where(classes==0)]
vecs_right = node.vecs.iloc[np.where(classes==1)]
</pre>
Given the final assignment of words to leaves, a codeword for each word in the vocabulary can be computed, where the n’th bit is set to 0 if the path from the root to that word takes the left child node at the n’th level of the tree, and 1 if it takes the right child node. The resulting data of vocabulary words together with code words and an enumeration of the internal nodes of the tree can then be fed into our modified version of fastText to use this semantic tree instead of the Huffman tree.
Inspecting the resulting tree
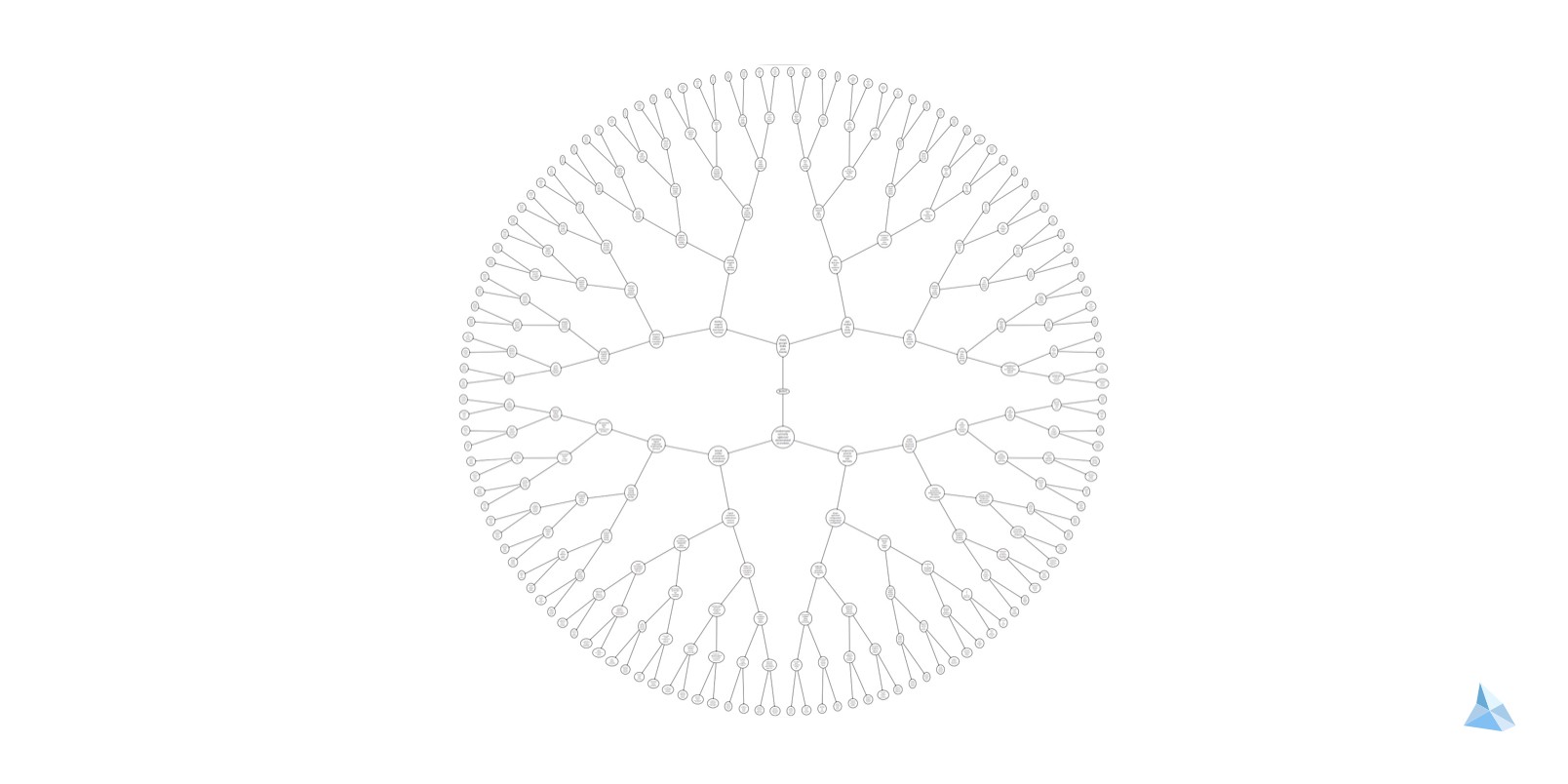
Given that we expect a semantic structure to emerge from the clustering, we wanted to check this subjectively by visualizing the resulting trees. To that end, a node was represented by the words most similar to its component mean vector from the GMM training. Then the Graphviz visualization library was used to construct images at different levels of the tree.
A semantic tree, truncated at the eighth level, looks like this:

Zooming in on the root node, it is very interesting to compare the most representative words for the two child nodes. One could say that one node is best described by persons and emotions whereas the other one represents rationality and objectivity.

Some further splits into more and more refined categories can be observed at deeper levels of the tree:


Evaluation
We trained two models, one using the Huffman tree and one using the semantic tree constructed as above. Other than the difference in trees, the hyperparameters were identical in the two cases. For evaluation we used the original word analogy task of word2vec and a word similarity task based on the Stanford rare words (rw) similarity dataset (see here for details). The word analogy evaluation was run using Gensim’s built-in accuracy function, whereas the word similarity evaluation is based on this evaluation script provided in the fastText repository. For the word analogy task, only the most frequent 30,000 words are considered.
The resulting scores can be seen in the figures below:


In general, the semantic tree outperforms the Huffman tree. However, this effect lessens as the dimension of the embedding increases. Interestingly, this is exactly the same as observed by Mnih and Hinton for the perplexity of language models, despite language modelling being a different task than word analogy and similarity learning.
The vocabulary resulting from the minCount cutoff contained 213,480 words. Clustering the word vectors in dimension 400 took around 13 minutes, which seems pretty efficient. Another interesting thing that could be observed was that the average logistic loss that is reported by fastText was less for the semantic tree than for the Huffman tree at the end of training. This confirms the hypothesis that it is easier to learn good classifiers along the tree nodes if the partition makes sense semantically.
Code
The code for running the experiments is available via GitHub. The modified version of fastText can be found in this repository and an iPython notebook for running the full experiment is available here. The Wikipedia dump we used for training is made available here. Otherwise, any public corpus of a decent size should lead to similar results. You might want try out the dataset used in this example.
References
Goodman, J. (2001). Classes for fast maximum entropy training. ICASSP 2001, Utah. pdf
Morin, F., & Bengio, Y. (2005). Hierarchical Probabilistic Neural Network Language Model. Aistats, 5. pdf
Mnih, A., & Hinton, G. E. (2008). A Scalable Hierarchical Distributed Language Model. Advances in Neural Information Processing Systems, 1–8. pdf
Mikolov, T. et. al. (2013). Efficient Estimation of Word Representations in Vector Space. Arxiv. pdf




